Data Intelligence¶
Data Intelligence serves as a valuable tool that enables automatic and intelligent analysis of datasets for classification tasks. Anomaly detection can be regarded as binary classification. This section describes the dataset analysis process. It outlines the steps required to refine and recollect data for improved performance. It also explains how insights are derived from the analysis results.
Importance of Data Intelligence¶
Users usually import time series datasets based on their own knowledge. However, due to some limitations, a comprehensive analysis of the data can yield unsatisfactory results. For example, the sampling frequency can be higher than what the application requires. Also, the training data for a classification task can be unevenly distributed across different classes.
To address these challenges, the Data Intelligence tool helps assess the balance of the dataset and identify the significance of each data channel/axis. The tool not only flags unbalanced datasets but also suggests redundant channels for omission. Furthermore, the tool helps determine the optimal sampling frequency and window size, enabling you to refine the datasets for improved quality and analysis outcomes.
Data Settings¶
The first step is to configure the mandatory parameters for the imported data.
Enter the following information:
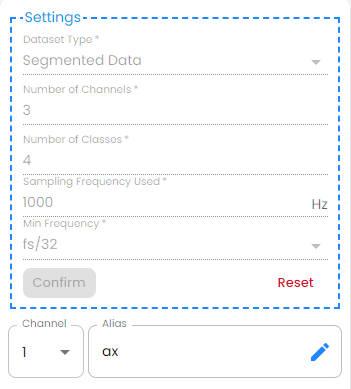
Dataset Type: Segmented or Continuous
Number of Channels: How many channels for each data point
Number of Classes: How many classes to be analyzed
Sampling Frequency Used: The sampling frequency of the data
Minimum Frequency: The lowest settable frequency division coefficient
Once the number of channels is set, you can assign individual aliases to each channel, which aids in distinguishing between channels and understanding the analysis report.
For example, the following figure shows the settings for importing the segmented fan state classification dataset for analysis.
Steps:
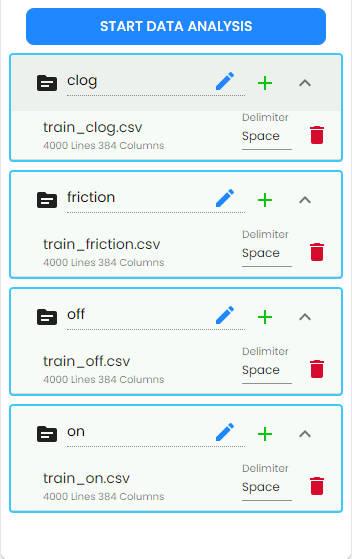
Click the
+button beside each class and load files.Verify that the automatically recognized Delimiter, number of lines, and number of columns are correct.
Ensure that each file conforms to the specified settings:
For segmented data: The number of columns must equal the window size multiplied by the number of channels.
For continuous data: The number of columns must equal the number of channels.
Optionally modify the alias for each category to facilitate differentiation.
Click the
START DATA ANALYSISbutton and proceed with data analysis and generate a report.
Analysis Result¶
Once you initiate the analysis, the system processes the data for a few seconds and then displays the results.
Data Balance¶

A five-star rating indicates a perfectly balanced dataset, which is optimal for classification tasks.
Channel Correlation¶

Note: This feature is applicable only when the number of channels is 2 or more.
Description:
Displays a confusion matrix table that illustrates the correlation values between different channels
The higher the absolute value, the higher the correlation between channels
Values closer to zero indicate that the channels are independent from each other
This information can be used to identify and potentially remove redundant channels, helping optimize the dataset for the training step
Channel Importance¶

Note: This feature is applicable only for segmented datasets with 2 or more channels.
Description:
Displays the importance scores for each channel in ranking bars
Higher scores indicate greater importance
Best Sampling Params¶

Parameters:
Sampling Frequency:
Outputs a recommended division frequency of the original sampling frequency
This recommendation is designed to help remove potential high-frequency noise components from the data
By reducing the frequency in this manner, you can save resources and power while maintaining essential information
Window Size:
Outputs a recommended window size
Remains unchanged for segmented data
Only valid for continuous data
Sampling Duration:
The sampling time for a single segmented sample data
Distinction Score:
Note: This metric is applicable only for continuous data.
Outputs the data differentiation score for continuous data under the optimal segmentation window size and sampling frequency
Continuous Data Example¶
Here, we provide an example of a continuous dataset. This dataset represents three-axis acceleration measurements at different states of a fan:
The dataset consists of three channels (three acceleration axes)
Each data file represents a fan state
The sampling frequency is 200 Hz
Each data file contains 720,001 lines with three channels per line
Follow the steps above for data settings and load data for smart analysis.
Analysis Output¶
Data Balance:

Data balanced with five stars
Channel Correlation:

The correlation between channels is low, indicating that there are no redundant channels
Best Sampling Params:
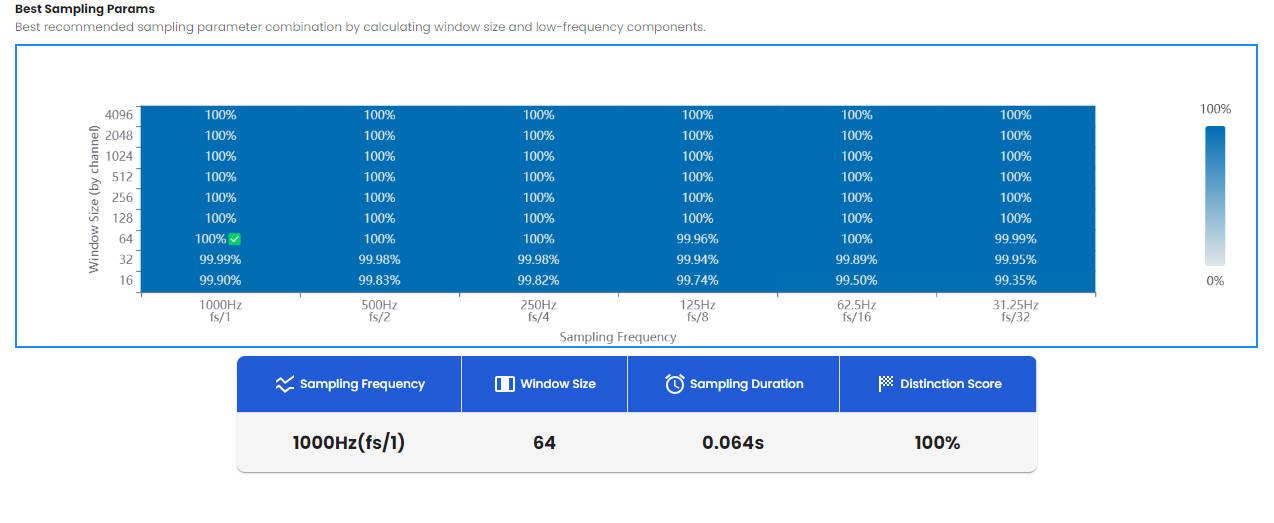
In the window size and sampling frequency matrix, the combination of a frequency of fs/1 and a window size of 64 is the most recommended
Applying Recommendations¶
You can import continuous data into Data Operation and use the Generate Samples operation with the recommended sampling parameters to generate sample datasets for machine learning projects.
Important: If the recommended sampling frequency is not fs/1, the data should be downsampled according to the division frequency and the recommended window size.
For example, if you get fs/2 division frequency after smart analysis, then the dataset is downsampled and saved as shown below:

Saving the Report¶
Finally, you can choose the quality and click the Save PDF button to save the analysis report PDF to the local system.

Conclusion¶
The Data Intelligence tool automatically generates reports on the quality of datasets and provides feedback to users without direct engineering support from NXP. The analyzed features include Data Balance, Channel Correlation, Channel Importance, and Best Sampling Params. These features empower you to make informed decisions regarding data recollection or reformatting, ensuring that your datasets are in an optimal state for subsequent processing.