Data Operation¶
The Data Operation module is a convenient and practical tool in TSS that bridges the gap between unstructured tabular data and the standardized signal formats required for TSS projects. Unlike images, time series data comes from a wide range of sources and exists in various forms. You may work with data from ad hoc sources, such as lab equipment and legacy systems that lack consistent formatting, making TSS import challenging for machine learning tasks. This tool empowers users to preprocess, transform, and validate heterogeneous time-series data into compliant input files for TSS workflows.
Dataset¶
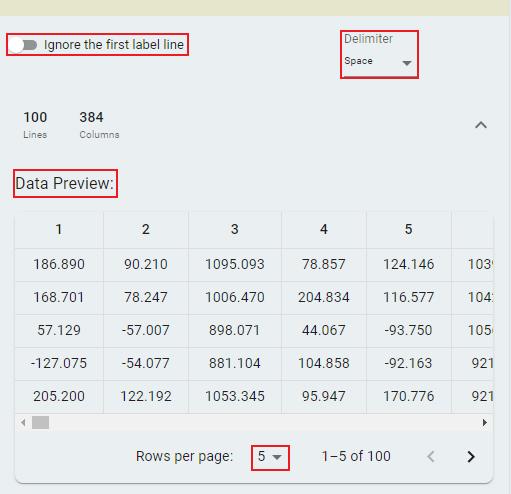
The Dataset section enables you to import tabular data files (in TXT or CSV format) for further processing. You can load single or multiple files, with validation rules ensuring data consistency.
To select files from the local system, click the Import Files button. Multiple files can be imported simultaneously.

To configure file parsing settings:
Click
Ignore the first label lineto skip the first line (header) if the table contains column headersManually select the appropriate
Delimiterto reload files
Operation¶
The Operation section allows users to apply various data transformations to the imported dataset. Most operations require parameter configuration to achieve the desired results.
Remove Lines¶
Remove lines that are unnecessary.
Steps:
Input the
Line(s) to removeaccording to the specified formatClick the
Runbutton
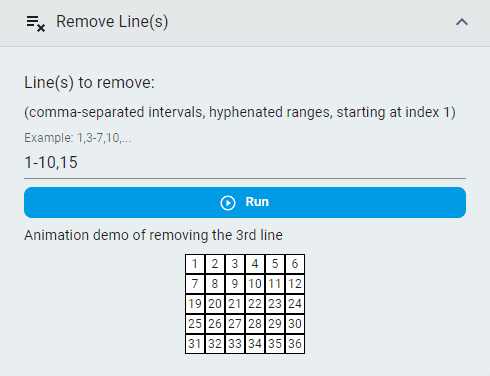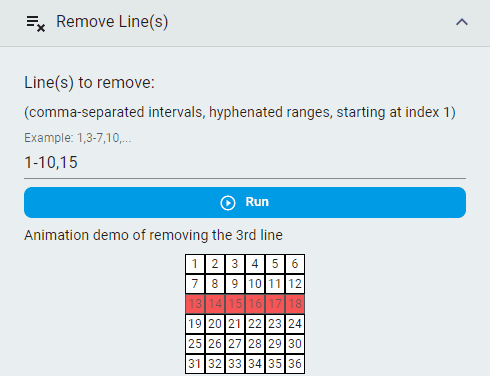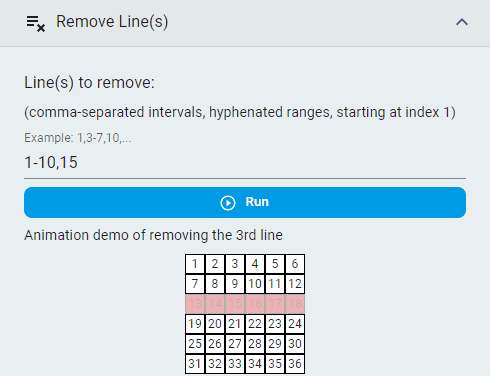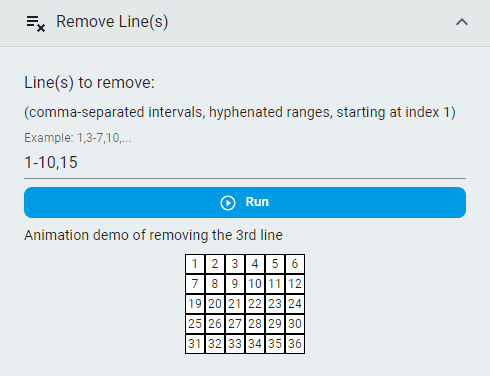
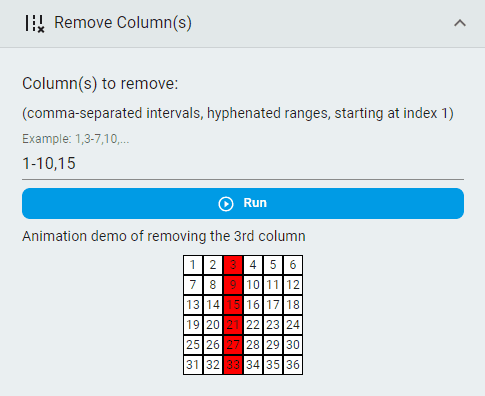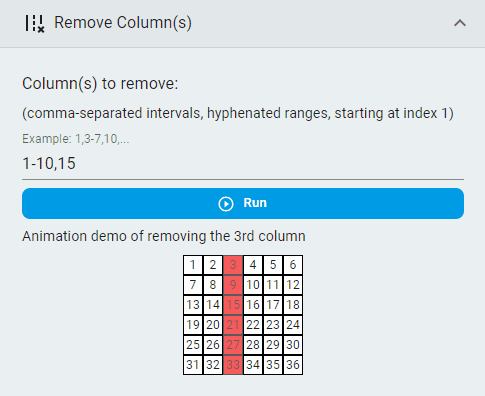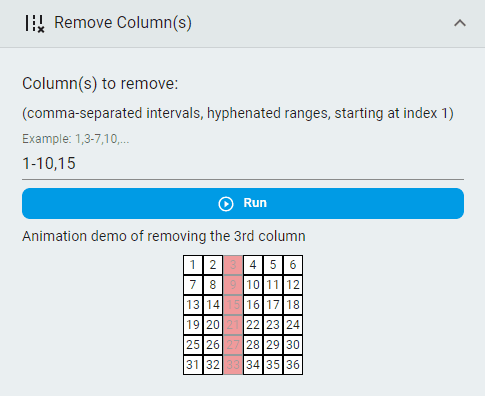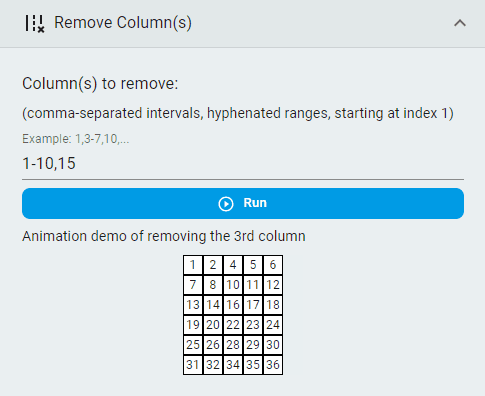
Remove Columns¶
Remove columns that are unnecessary.
Steps:
Input the
Column(s) to removeaccording to the specified formatClick the
Runbutton
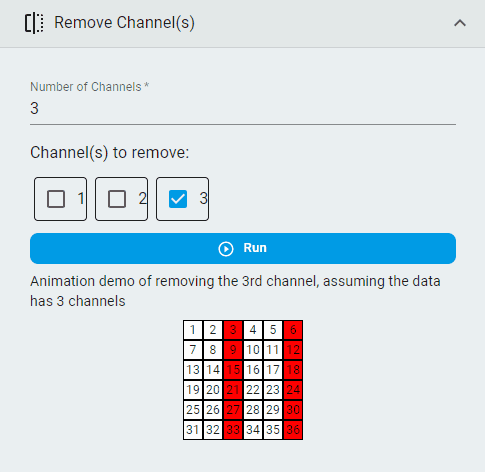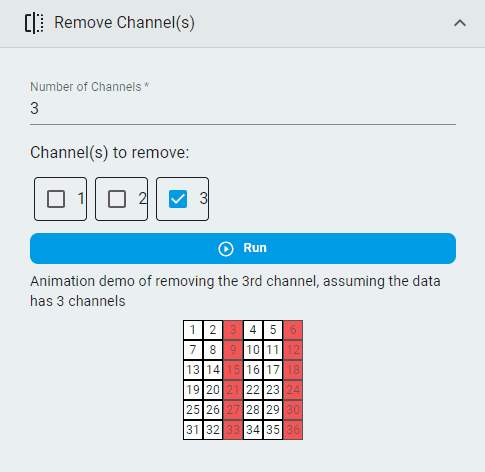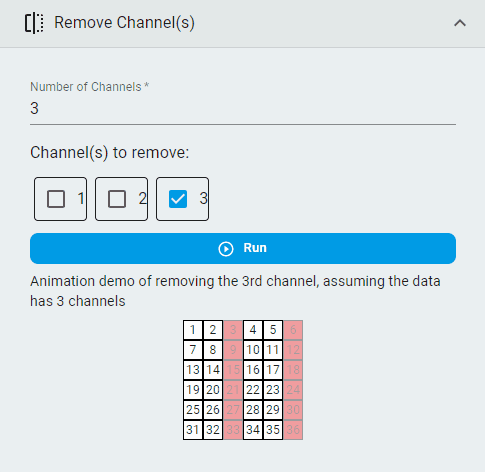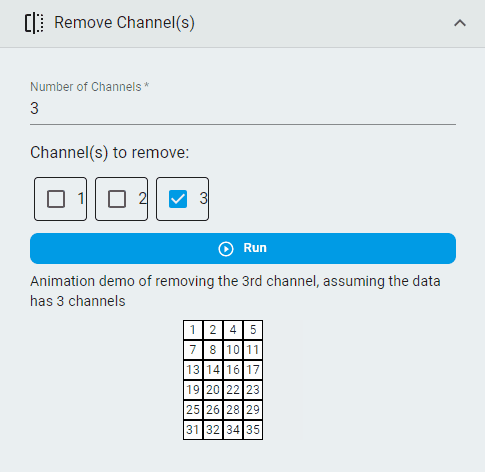
Remove Channels¶
Remove channels that are unnecessary.
Note: This operation is available only for multichannel data. You can get recommendations by applying the data to Data Intelligence for smart analysis. The Channel Correlation and Channel Importance indices can help identify redundant channels.
Steps:
Set the
Number of ChannelsSelect the
Channel(s) to removeClick the
Runbutton
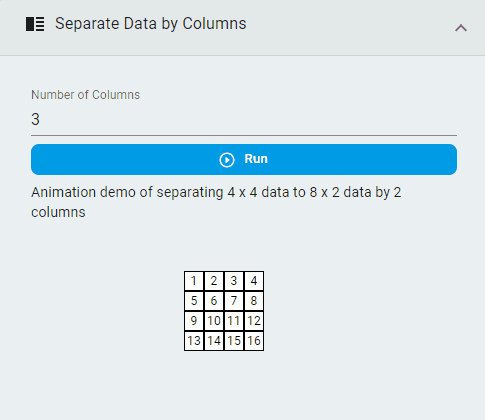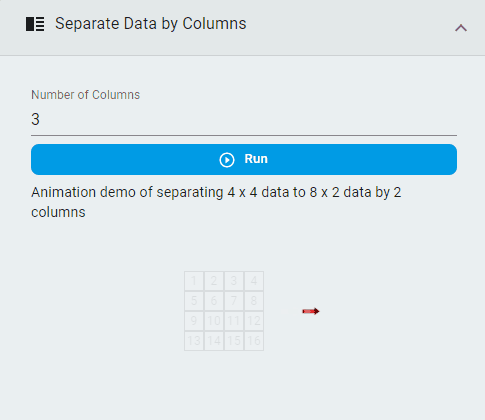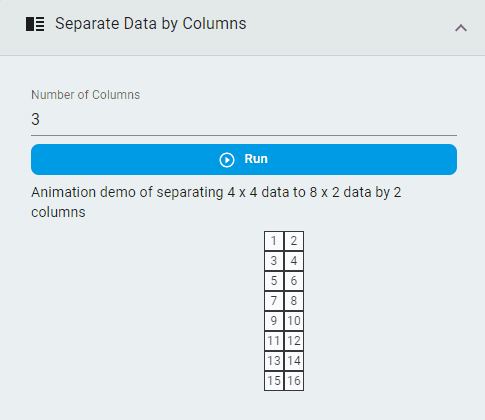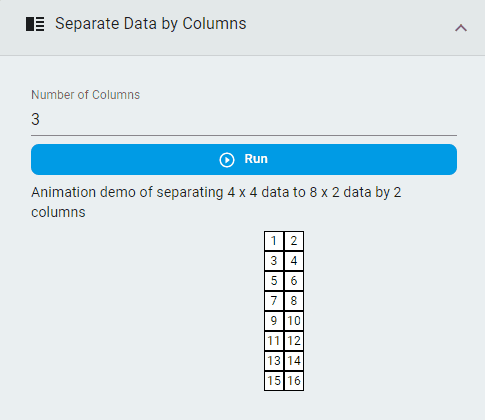
Separate Data by Columns¶
Rearrange the data according to the number of columns specified.
Steps:
Set the
Number of ColumnsClick the
Runbutton
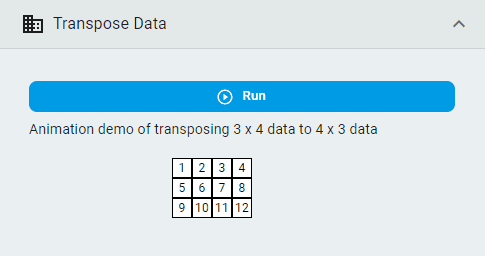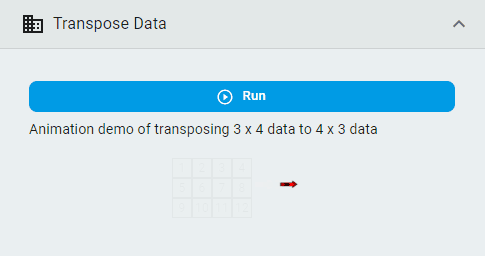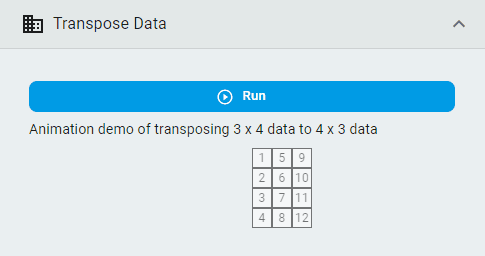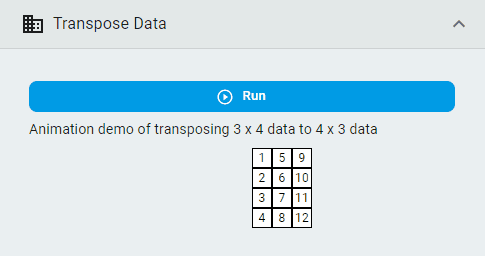
Transpose Data¶
Transpose the dataset so that rows become columns and columns become rows.
Simply click the Run button.
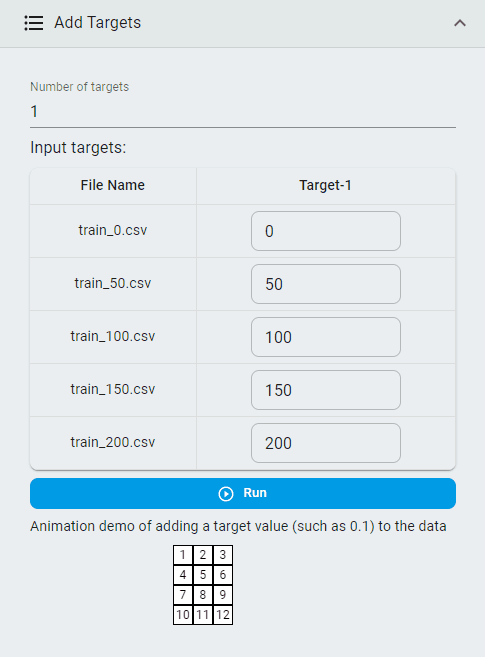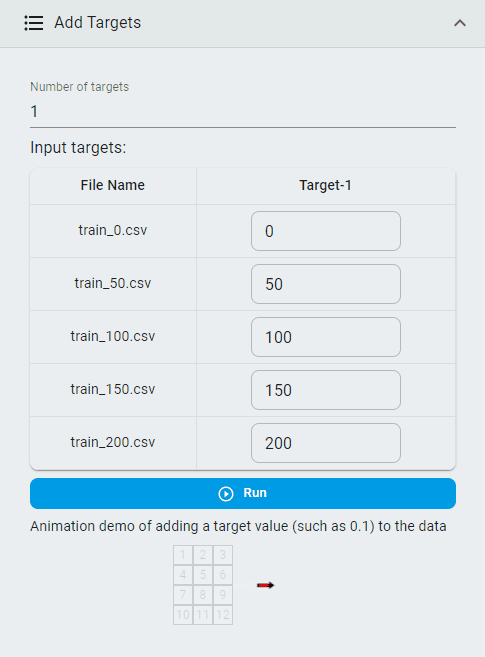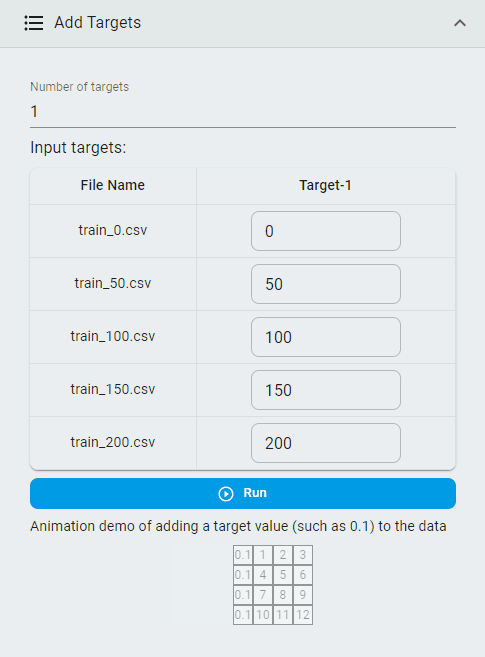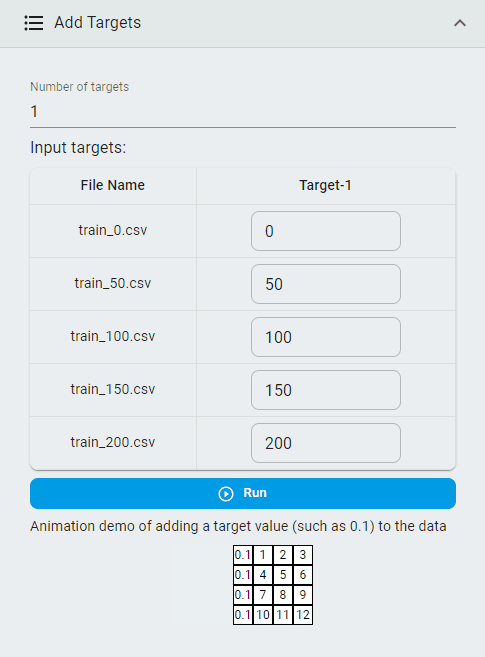
Add Targets¶
Add target values to classification datasets so that classification datasets can be converted into regression datasets.
Steps:
Set the
Number of targetsInput the target values for each file
Click the
Runbutton
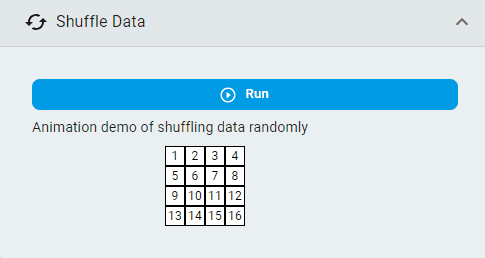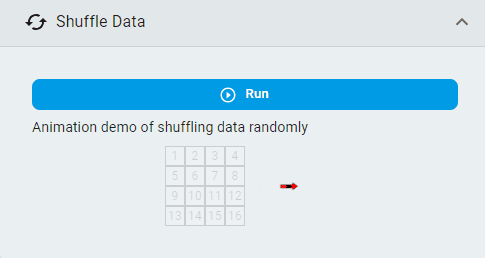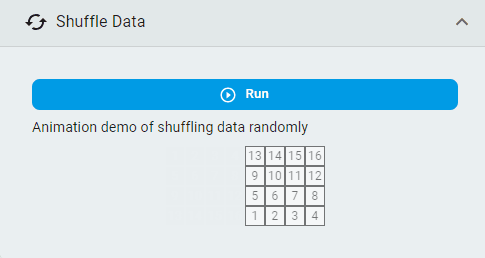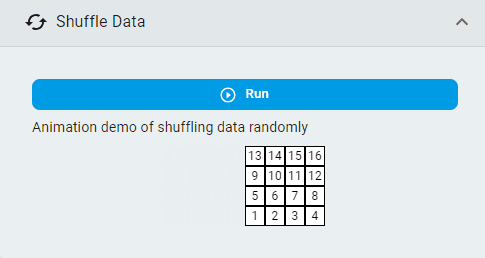
Shuffle Data¶
Shuffle the dataset by lines.
Simply click the Run button.
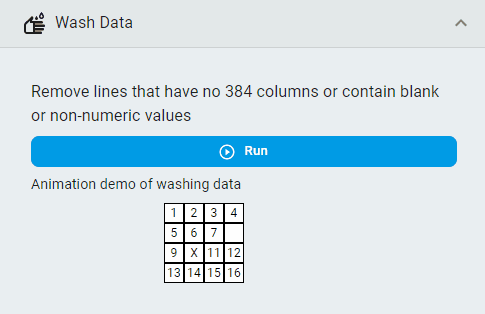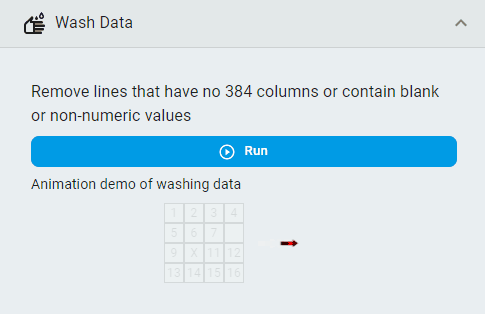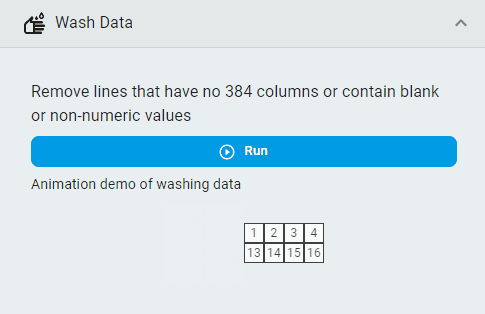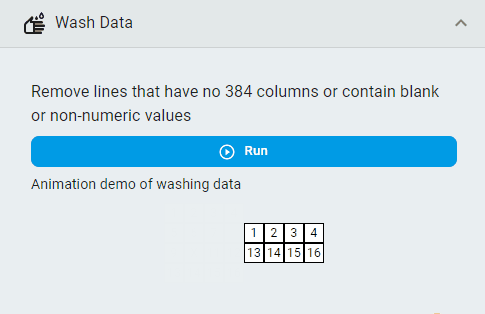
Wash Data¶
Remove unclean lines from the dataset.
Note: “Unclean” means that the line contains non-numeric elements, or the number of columns in the line is inconsistent with other lines.
Simply click the Run button.
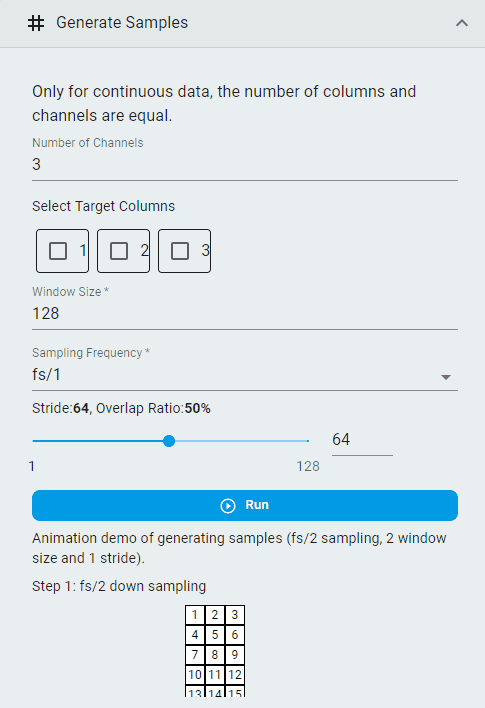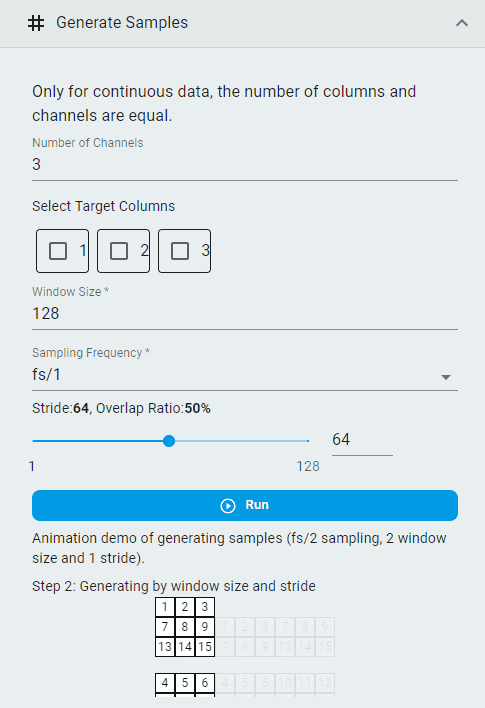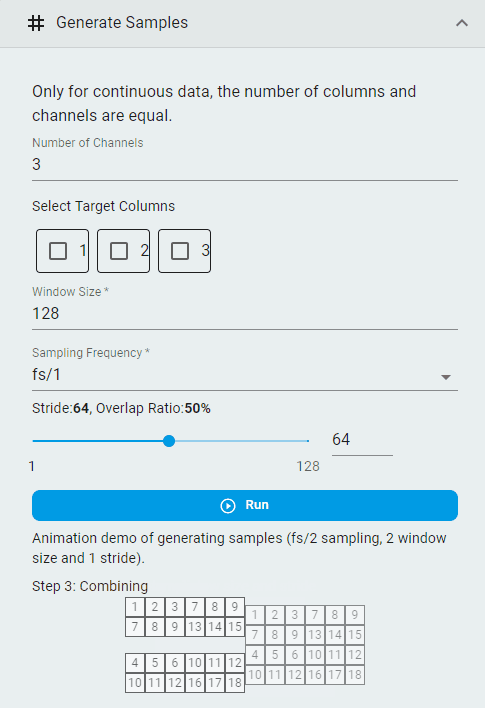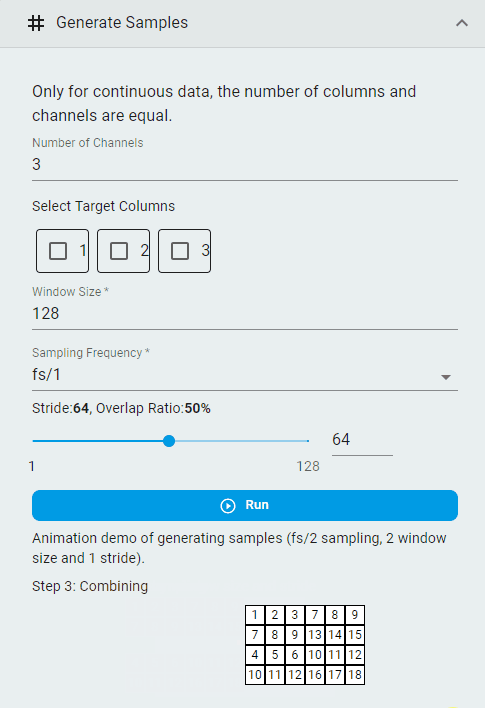
Generate Samples¶
Create segmented datasets from continuous data for importing into TSS machine learning projects.
Note: You can use Data Intelligence to perform smart analysis on continuous data in advance and obtain optimal segmentation parameters.
Steps:
Set the
Number of ChannelsImportant: Continuous data requires the number of channels to match the number of columns.
Select the
Target ColumnsNote: This option is available when you wish to use a channel’s output as the prediction target for regression tasks. It is not required for classification tasks.
Set the
Window SizeSet the
Sampling Frequency(the frequency division factor of the original sampling frequency)Set the
Strideand theOverlap RatioClick the
Runbutton
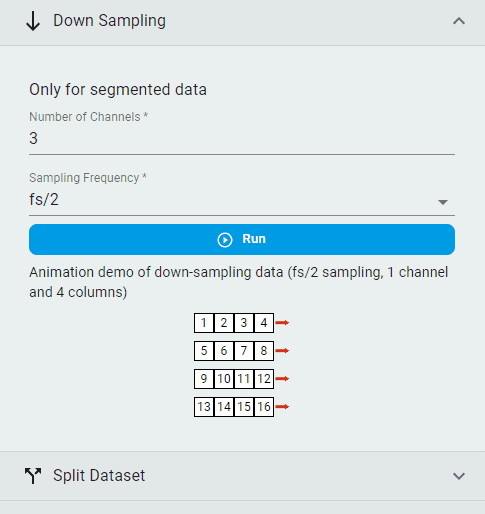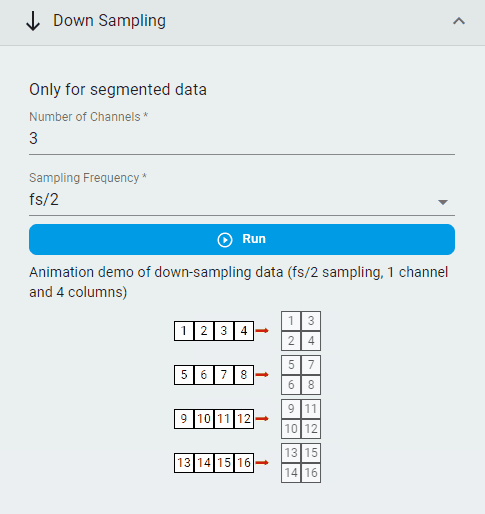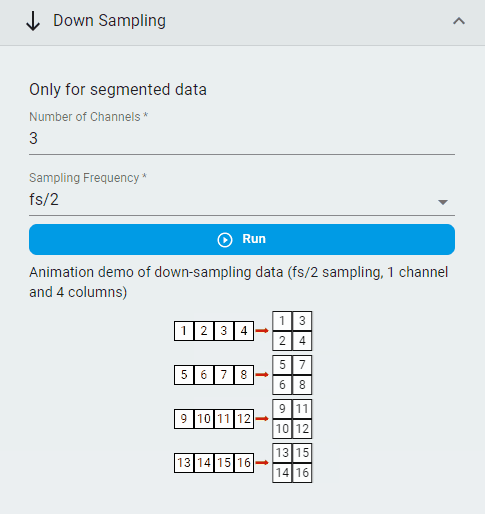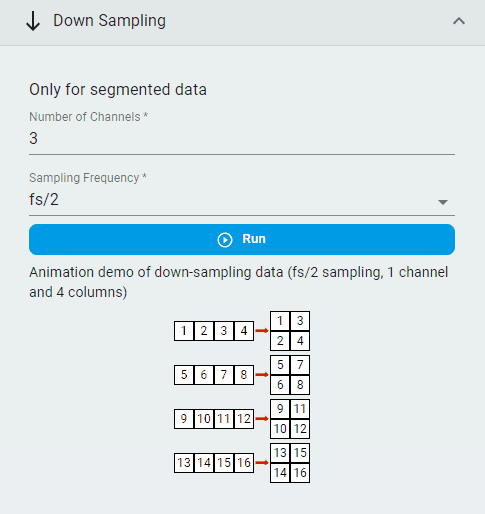
Down Sampling¶
Downsample the segmented dataset.
Note: Since the window size of segmented data is fixed, the window size of the data decreases when downsampling.
Steps:
Set the
Number of ChannelsSet the
Sampling FrequencyClick the
Runbutton
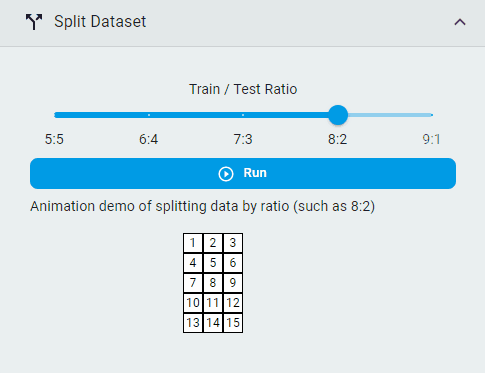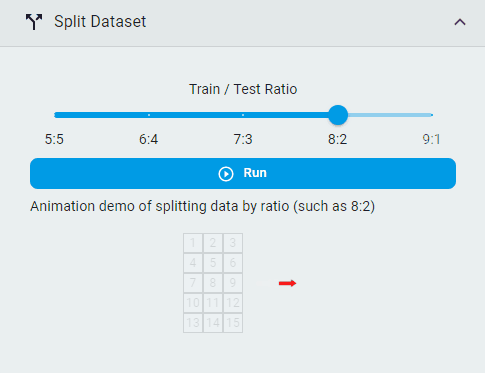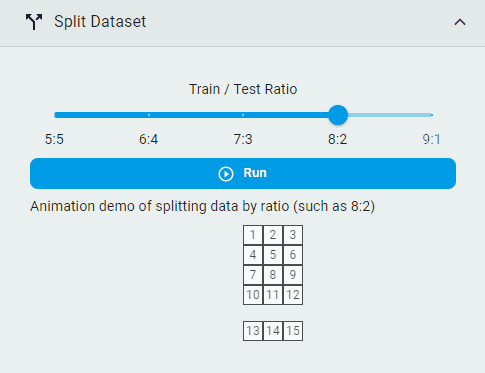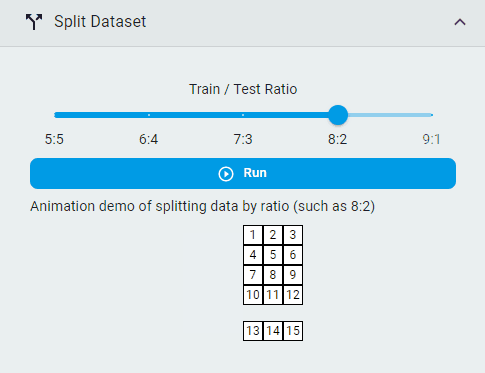
Split Dataset¶
Split the dataset into training and test sets by lines.
Steps:
Select the
Train/Test RatioClick the
Runbutton
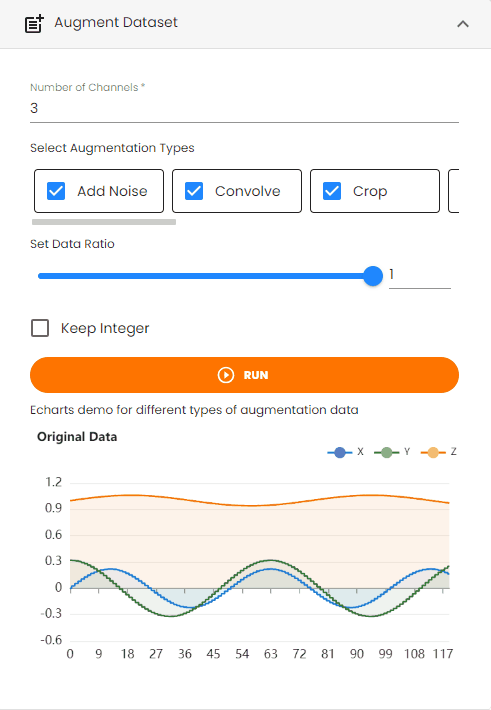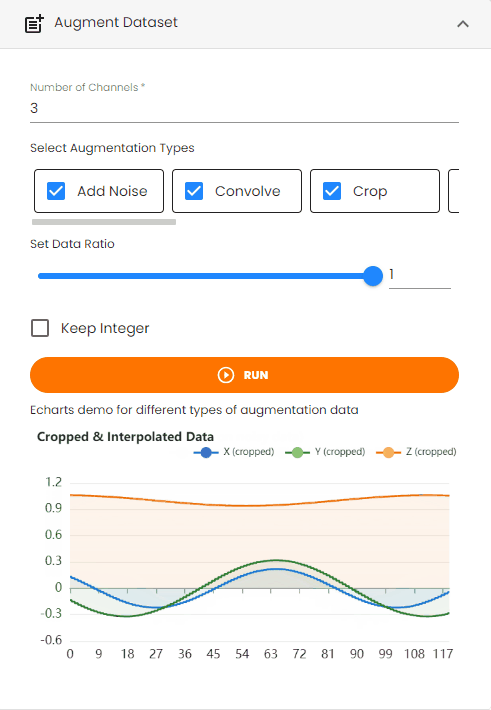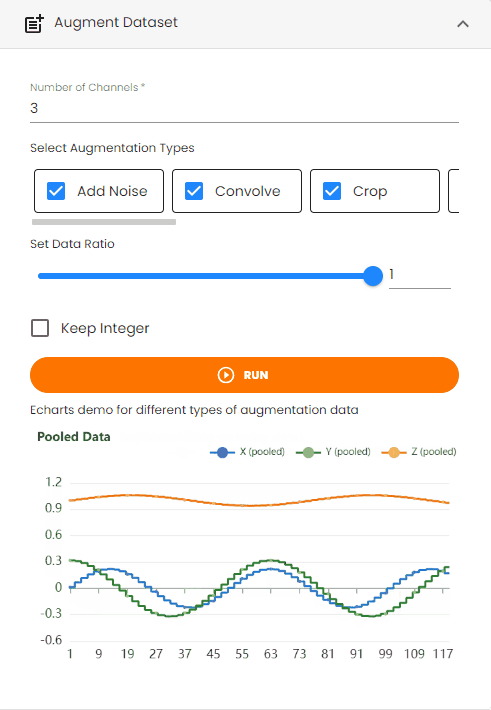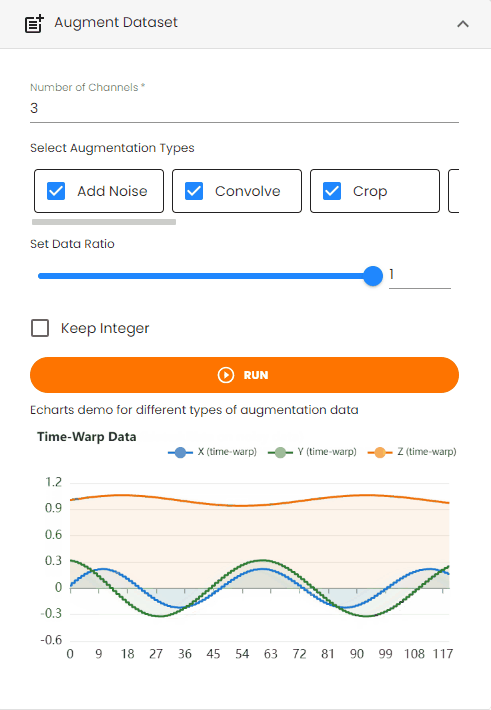
Augment Dataset¶
Augment the dataset by applying transformations to increase data volume and diversity for improving model robustness.
Steps:
Set the
Number of ChannelsSelect the
Augmentation Typesto choose from available transformations:Add Noise: Adds random noise to the data to simulate real-world variations
Convolve: Applies convolution operations to the data
Crop: Randomly crops segments of the data
Drift: Introduces gradual drift in the signal values
Dropout: Randomly masks the values of some time steps
Pool: Applies pooling operations to reduce data dimensionality
Quantize: Reduces the precision of data values through quantization
Reverse: Reverses the order of time steps in the data
Time Warp: Applies time warping transformations to the data
Set the
Data Ratioto control the augmented data file sizeEnable
Keep Integerto preserve integer data types (if the original time series data is integer type)Click the
Runbutton
Concatenate Files¶
Merge multiple files vertically (row-wise) or horizontally (column-wise).
Steps:
Choose concatenation
DirectionClick the
Runbutton

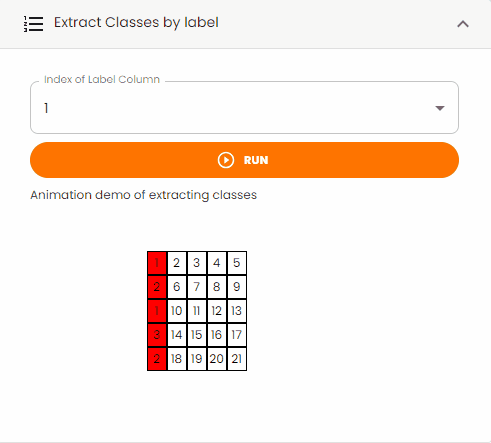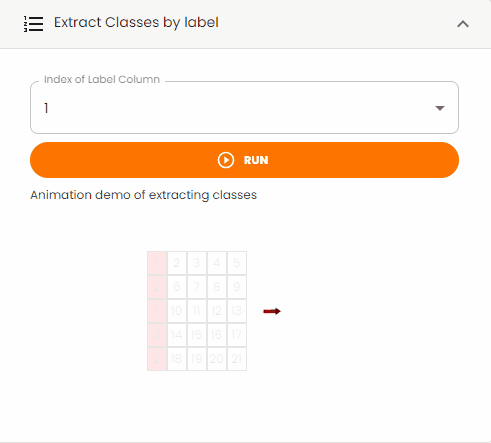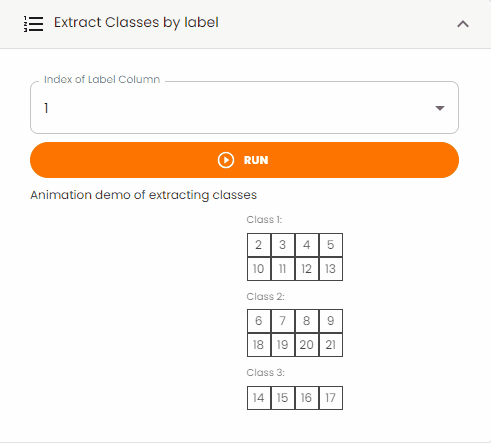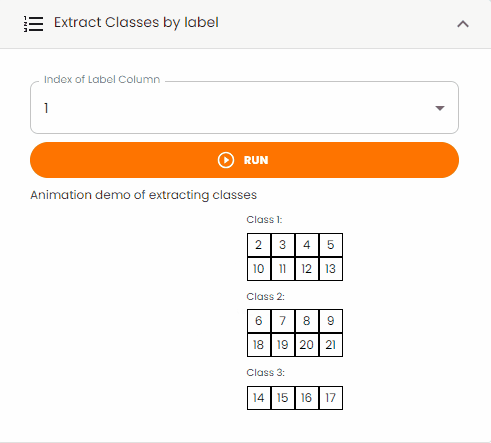
Extract Classes by Label¶
Extract specific classes from the dataset based on label values.
Note: Some tabular data might contain a label column that identifies different classes or categories.
Steps:
Set the
Index of Label Columnto specify which column contains the class labelsClick the
Runbutton
Result¶
The Result section allows you to save the processed files or perform new operations on them.
For individual files:
Click
Run New Operationto import the file to the Dataset sectionClick
Save Asto save the processed file to the local system
For multiple files:
Click
Run New Operationto import all files to the Dataset sectionClick
Save Allto package the processed files into a zip file and save it

Conclusion¶
The Data Operation module provides a streamlined workflow for preprocessing and transforming raw tabular data into TSS-compatible signal files. The interface is divided into three key sections:
Dataset: Enables flexible file (TXT/CSV) importing with configurable parsing settings (delimiters, headers)
Operation: Provides various operations that can perform different transformations on different types of tabular data, with each operation being simple and easy to understand
Result: Enables you to choose whether to run new operations or save files after processing
The intuitive design of this tool helps both novices and experienced analysts quickly prepare optimal time-series datasets for their projects.